viterbi算法
维特比算法说白了就是动态规划实现最短路径,只要知道动态规划是通过空间换时间的一种方法就可以了。HMM的解码部分使用的是viterbi算法。
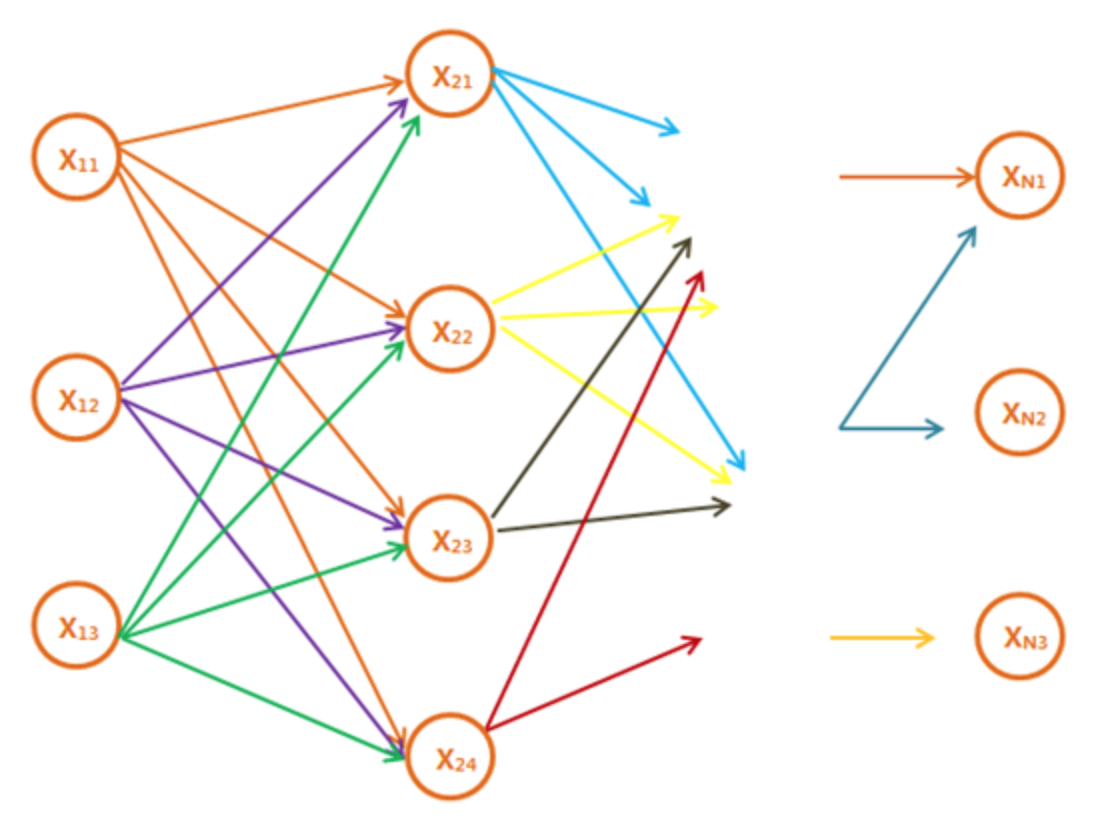
假设上图每一列分别有$ n _ {1},…,n _ {n} $个节点,如果不使用动态的话,那么计算最短路径的时间复杂度就是$ O(n _ {1} * n _ {2} * … * n _ {n}) $。
维特比算法的精髓就是,既然知道到第i列所有节点Xj{j=1,2,3…}的最短路径,那么到第i+1列节点的最短路径就等于到第i列j个节点的最短路径+第i列j个节点到第i+1列各个节点的距离的最小值。
分析一下复杂度,假设整个有向无环图中每一列节点最多有D个(也就是图的宽度为D),并且图一共有N列,那么,每次计算至多计算D*D次(i列的D个节点到i+1列D个节点的距离)。至多计算N次。那么时间复杂度为O(ND^2),远远小于穷举法O(D^N)。