概述
现有的高斯模型有单高斯模型(SGM)和高斯混合模型(GMM)两种。从几何上讲,单高斯分布模型在二维空间上近似于椭圆,在三维空间上近似于椭球。 在很多情况下,属于同一类别的样本点并不满足椭圆分布的特性,所以我们需要引入混合高斯模型来解决这种情况。
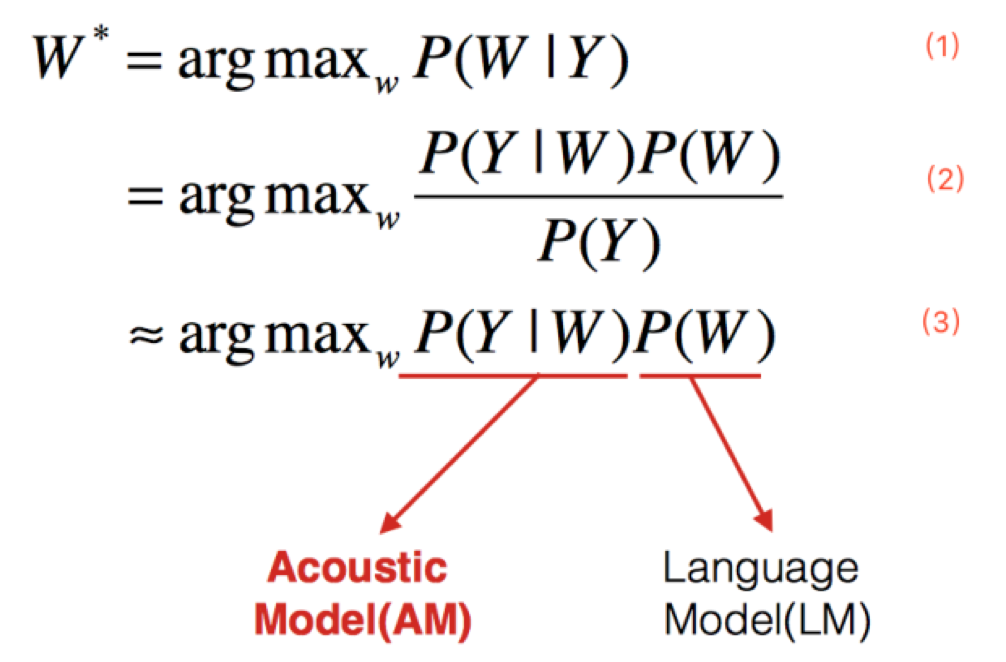
在DNN兴盛之前,高斯混合模型(GMM, Gaussian Mixture Model)广泛应用在语音识别的声学模型建模中,即使现在,在训练DNN模型之前依然需要通过GMM模型进行迭代,以及进行强制对齐。因此想要对语音识别技术有一定的了解,对于GMM模型的了解是必不可少的。