语音识别基本架构
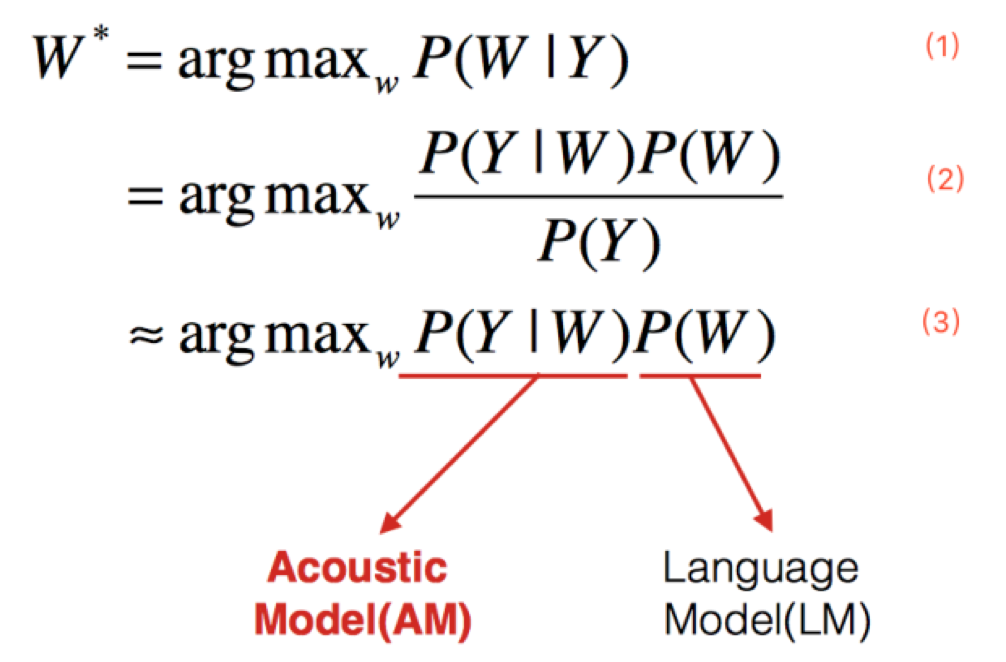
上式中W表示文字序列,Y表示语音输入。
公式1表示语音识别的目标是在给定语音输入的情况下,找到可能性最大的文字序列。
根据贝叶斯定理,可以得到公式2,其中分母表示出现这条语音的概率,它相比于求解的文字序列没有参数关系,可以在求解时忽略,进而得到公式3。
公式3中第一部分表示给定一个文字序列出现这条音频的概率,它就是语音识别中的声学模型;第二部分表示出现这个文字序列的概率,它就是语音识别中的语言模型。
无论是传统的方法也好,现在火热的深度神经网络的方法也罢,目前的语音识别在架构上都没有脱离上面的公式,也就是说都离不开AM和LM。
下面分别对这两部分进行介绍。
声学模型(Acoustic Model,AM)
声学模型可以理解为是对发声的建模,它能够把语音输入转换成声学表示的输出,更准确的说是给出语音属于某个声学符号的概率。在英文中这个声学符号可以是音节或者更小的颗粒度音素(phone);在中文中这个声学符号可以是声韵母或者是颗粒度同英文一样小的音素。
CD-DNN—HMM模型
公式3中的声学模型就可以表示为下面公式4的形式:

其中Q表示发音单位的序列。从公式中可以看到,声学模型最终转换成了一个语音到发音序列的模型和一个发音序列到输出文字序列的字典。这里的发音序列通常是音素,到此为止声学模型是从语音到音素状态的一个描述。
为了对不同上下文的音素加以区分,通常使用上下文相关的“三音子”作为建模单元。可以用下图表示:

公式4中的字典部分表示为如下公式5,其意义是把每个文字拆分成若干发音符号的序列。

公式4中的声学部分可以继续分解为如下公式6:

公式6表示声学建模的颗粒度可以继续分解为更小的状态(state)。通常一个三音子对应有3个状态(静音通常是5个状态),那么声学建模的总数就是3*Q^3+5这么多。为了压缩建模单元数量,状态绑定的技术被大量使用,它使得发音类似的状态用一个模型表示,从而减少了参数量。具体绑定形式如下图所示:

基于上面的推导,声学模型是一个描述语音和状态之间转换的模型。
此时,引入HMM假设:状态是隐变量,语音是观测值,状态之间的跳转符合马尔科夫假设。那么声学模型可以继续表示为如下公式:

其中a表示转移概率,b表示发射概率。用图来表示的话就是下图中的结构:

如图中所示,观测概率通常用GMM或是DNN来描述。这就是CD-GMM-HMM架构和CD-DNN-HMM架构的语音识别声学模型。CD-DNN-HMM的架构图表示如下:

CTC模型
在基于CD-DNN-HMM架构的语音识别声学模型中,训练DNN通常需要帧对齐标签。在GMM中,这个对齐操作是通过EM算法不断迭代完成的。
- E-step:估计(重估)GMM参数
- M-step:使用BW(Baum-Welch算法)对齐
此外对于HMM假设一直受到诟病,等到RNN出现之后,使用RNN来对时序关系进行描述来取代HMM成为当时的热潮。
随着神经网络优化技术的发展和GPU计算能力的不断提升,最终使用RNN和CTC来进行建模实现了end-to-end语音识别的声学模型。
CTC的全称是Connectionist Temporal Classification,中文翻译大概是连接时序分类。它要达到的目标就是直接将语音和相应的文字对应起来,实现时序问题的分类。
用公式来描述的话,CTC的公式推导如下:
$$
p ( \pi | x ) = \prod _ { t = 1 } ^ { T } y _ { \pi _ { t } } ^ { t } , \forall \pi \in L ^ { T }
$$
其中π表示文字序列,X表示语音输入,y表示RNN的输出。由于很多帧可以输出同样的一个文字,同时很多帧也可以没有任何输出,因此定义了一个多对一的函数,把输出序列中重复的字符合并起来,形成唯一的序列,进而公式表示如下:
$$
p ( l | x ) = \sum _ { \pi \in \Re ^ { - 1 } ( l ) } p ( \pi | x )
$$
起始l表示对应的标注文本,而π是带有冗余的神经网络输出。求解上述公式,需要使用前后向算法。
前向因子:
$$
\alpha _ { t } ( s ) \stackrel { d e f } { = } \sum _ { \pi \in N ^ { t } : \Re \left( \pi _ { 1 : t } = l _ { 1 : s } \right) t ^ { \prime } = 1 } ^ { t } y _ { \pi _ { t } ^ { \prime } } ^ { t ^ { \prime } }
$$
后向因子:
$$
\beta _ { t } ( s ) = \sum _ { \pi \in \Re ^ { - 1 } ( l ) : \pi _ { t } = l _ { s } ^ { \prime } } y _ { l _ { s } ^ { \prime } } ^ { t } \prod _ { t = 1 } ^ { T } y _ { \pi _ { t } } ^ { t }
$$
那么神经网络的输出和前后向因子的关系可以表示为:
$$
\alpha _ { t } ( s ) \beta _ { t } ( s ) = \sum _ { \pi \in \Re ^ { - 1 } ( l ) : \pi _ { t } = l _ { s } ^ { \prime } } y _ { l _ { s } ^ { \prime } } ^ { t } \prod _ { t = 1 } ^ { T } y _ { \pi _ { t } } ^ { t }
$$
进而得到:
$$
p ( l | x ) = \sum _ { s = 1 } ^ { \left| l ^ { \prime } \right| } \frac { \alpha _ { t } ( s ) \beta _ { t } ( s ) } { y _ { l _ { s } ^ { t } } }
$$
利用上述公式,就可以进行神经网络的训练了,这里仍然可以描述为EM的思想:
- E步:使用BPTT算法优化神经网络参数;
- M步:使用神经网络的输出,重新寻找最优的对齐关系。
CTC可以看成是一个分类方法,甚至可以看作是目标函数。在构建end-to-end声学模型的过程中,CTC起到了很好的自动对齐的效果。同传统的基于CD-DNN-HMM的方法相比,对齐效果是这样的:

基于帧对齐的方法强制要求切分好的帧对齐到对应的标签上去,而CTC则可以时帧的输出为空,只有少数帧对齐到对应的输出标签上。
End-to-End模型
由于神经网络强大的建模能力,End-to-End的输出标签也不再需要像传统架构一样的进行细分。例如对于中文,输出不再需要进行细分为状态、音素或者声韵母,直接将汉字作为输出即可;对于英文,考虑到英文单词的数量庞大,可以使用字母作为输出标签。
从这一点出发,我们可以认为神经网络将声学符号到字符串的映射关系也一并建模学习了出来,这部分是在传统的框架中时词典所应承担的任务。针对这个模块,传统框架中有一个专门的建模单元叫做G2P(grapheme-to-phoneme),来处理集外词(out of vocabulary,OOV)。在End-to-End的声学模型中,可以没有词典,没有OOV,也没有G2P。这些全都被建模在一个神经网络中。
另外,在传统的框架结构中,语音需要分帧,加窗,提取特征(MFCC、PLP等)。在基于神经网络的声学模型中,通常使用更裸的Fbank特征。在End-to-End的识别中,使用更简单的特征比如FFT等也是常见的做法。或许在不久的将来,语音的采样点也可以作为输入,这就是更加彻底的End-to-End声学模型。
除此之外,End-to-End的声学模型中已经带有了语言模型的信息,它是通过RNN在输出序列上学习得到的。但这个语言模型仍然比较弱,如果外加一个更大数据量的语言模型,解码的效果会更好。因此,End-to-End现在指声学模型部分,等到不需要语言模型的时候,才是完全的End-to-End。
语言模型(Language Model, LM)
语言模型的作用之一为消解多音字的问题,在声学模型给出发音序列之后,从候选的文字序列中找出概率最大的字符串序列。
语言模型还会对声学的解码作约束和重打分,让最终识别结果符合语法规则。目前最常见的是N-Gram语言模型和基于RNN的语言模型。
解码
传统的语音识别解码都是建立在WFST的基础之上,它是将HMM、词典以及语言模型编译成一个网络。解码就是在这个WFST构造的动态网络空间中,找到最优的输出字符序列。搜索通常使用Viterbi算法,另外为了防止搜索空间爆炸,通常会采用剪枝算法,因此搜索得到的结果可能不是最优结果。
