声学模型网络
声学模型就是用来估计不同音素对某一帧语音的条件概率,最终找出哪一种音素序列最有可能呈现出系统接收到的波形。
DNN
DNN 是一个典型的前馈网络,语音特征在进入输入层之后,逐层传播,最终在输出层得出每个音素的概率。值得注意的是,DNN在输入层除了当前帧之外,还会额外接收相邻的帧,这使得 DNN 一方面能够捕捉更广阔的时域信息,同时能够学习到相邻帧之间的变化特点。在实际应用中,DNN 往往会接受连续 10~20 帧作为输入。
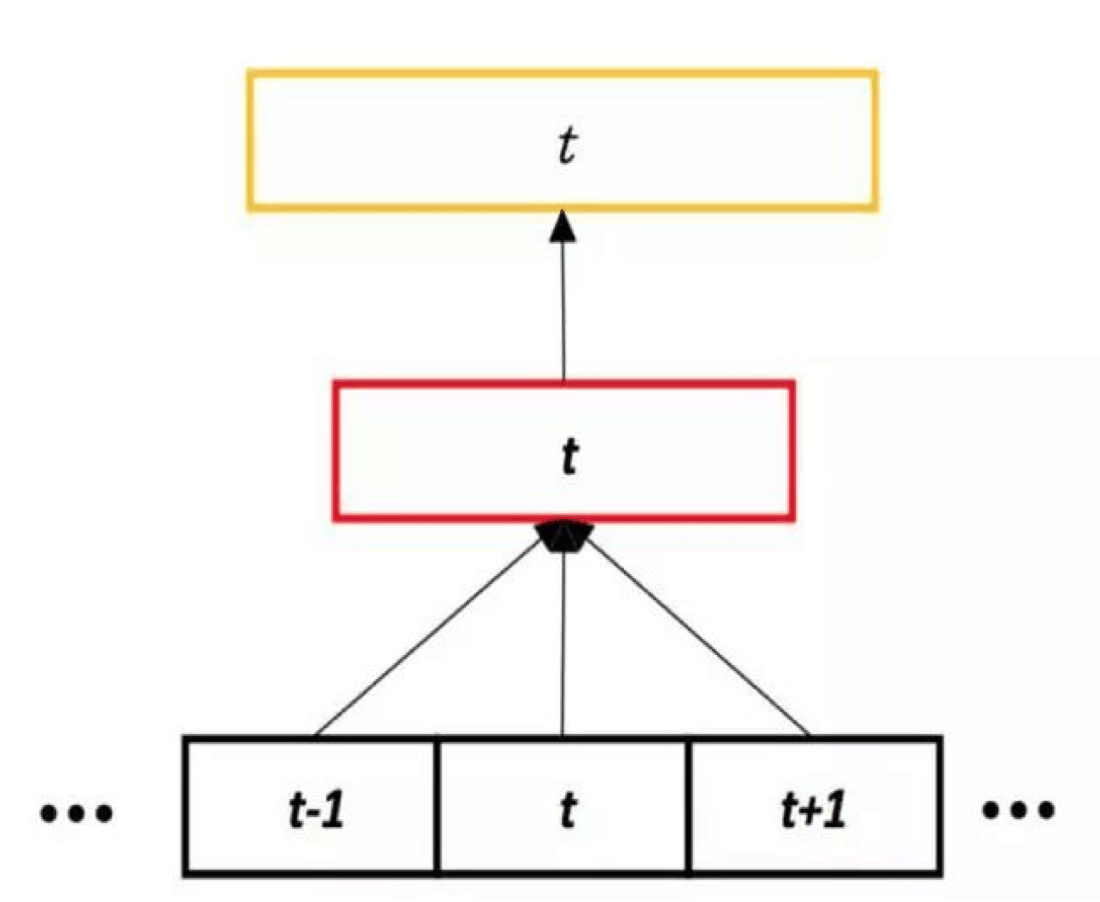
TDNN
TDNN与普通 DNN 类似,也是前馈网络,语音特征在网络内也是逐层向前传播,不同之处在于 TDNN 对隐层也做了上下文扩展。普通 DNN 每个隐层仅仅接收到前一个隐层的当前输出,而TDNN会将隐层的当前输出与其前后若干时刻的输出拼在一起,作为下一个隐层的输入。
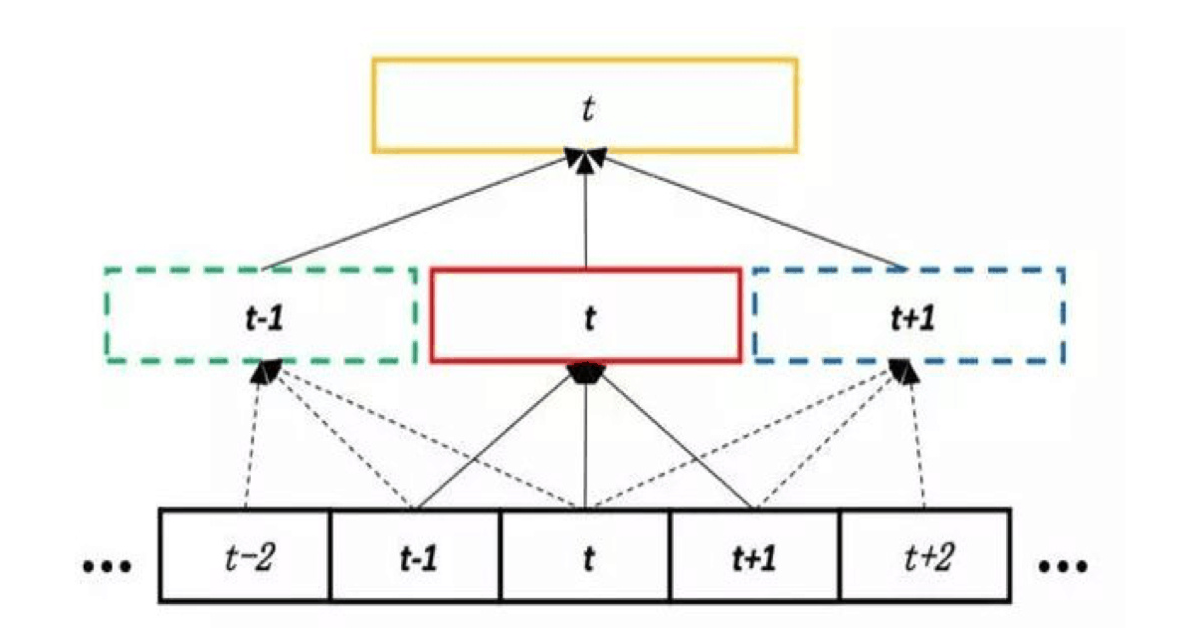
RNN
与 RNN 对比来看,DNN 和 TDNN 的每个隐层都只会接收前一个隐层的输出,而由于语音特征在网络中传播时存在回路,RNN 中的隐层除了接收前一个隐层的输出外,还会将自己前一时刻的输出重新输入给自己。这样的结构使得 RNN 在理论上可以学习到无限长度的历史信息,但是在训练过程中,也会面临着复杂度较高以及梯度消失的问题。
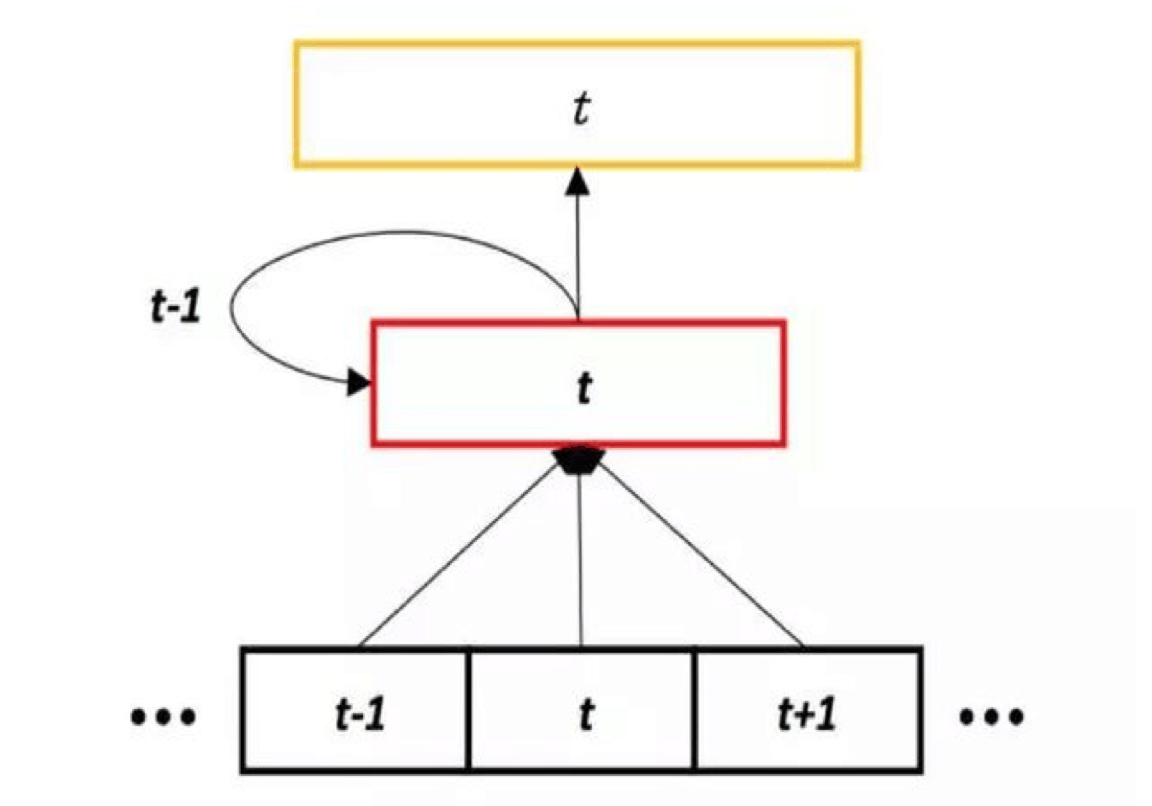
因为 RNN 模型有递归层的存在,导致很难像传统 DNN 那样进行并行化训练,同时与前馈神经网络相比 ,RNN 训练的复杂度要高很多,随之而来的问题就是模型训练时间过长。
而 TDNN 的优点在于不仅能够对长时间依赖性的语音信号进行建模,同时与传统DNN的训练和解码效率几乎相当。
Chain Model
TF-MMI
在语音识别领域,区分性训练(Discriminative Training)能够显著提升语音识别系统的性能。区分性训练需要所有的单词序列组合来做训练,一般而言我们会先利用交叉熵准则训练一个基准模型,配合使用一个相对较弱的语言模型生成相应的词图(Lattice)。Lattice里面除了包含与正确识别结果相对应的路径外,还包含了与正确路径足够接近的其他路径,区分性训练就是要提高模型走正确路径的概率,同时压低走相似路径的概率。
近年来CTC(Connectionist Temporal Classification)在语音识别领域受到很大关注,但CTC相比传统模型的优势,需要在很大的数据集上才能体现出来,而且CTC的训练速度很慢,参数调节更困难。与区分性训练中常用的MMI(Maximum Mutual Information)准则类似,CTC训练准则的目标是最大化正确标注的条件概率,而MMI着重优化正确路径和其他相似路径的概率差。
LF-MMI(Lattice-Free Maximum Mutual Information)训练准则通过在神经网络输出层计算出来所有可能的标注序列,根据这些标注序列计算出相应的MMI信息和相关的梯度,然后通过梯度传播算法完成训练。
LF-MMI训练准则能够在训练过程中直接计算所有可能路径的后验概率(Posterior Probability),省去了区分性训练前需要提前生成Lattice的麻烦,所以这种方法被叫做Lattice-Free MMI。
Chain Model在LF-MMI训练方法的基础上,还能够使用三分之一甚至更低的帧率、更简单的HMM拓扑结构来降低解码时间。
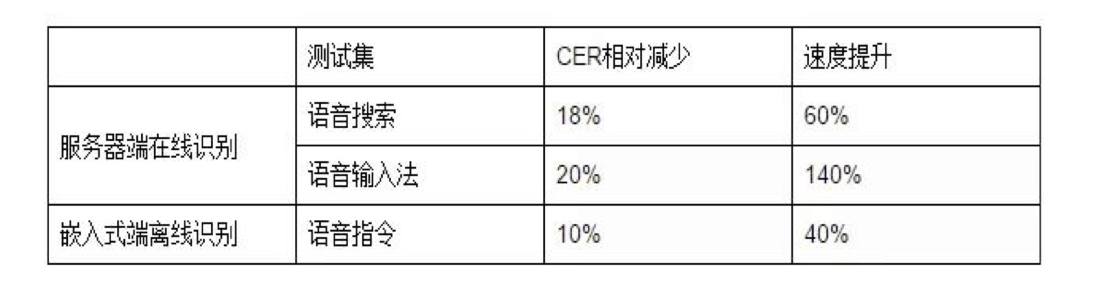
所谓的Chain Model就是结合了低帧率输出、优化过后的HMM拓扑结构和LF-MMI训练方法的语音识别系统。从实际效果来看,相对于主流的交叉熵模型系统,Chain Model搭配时延深度神经网络(TDNN),在语音识别系统的准确率(CER,字错误率)和解码速度上都获得了显著的提高。
topo
tdnn的输出帧速率是常规帧速率的1/3。这样做是因为从tdnn的网络结构来看相邻节点之间的变化较少,而且包含了大量重复信息,因此可以每隔几帧才计算一帧的结果,从而加速训练和解码过程。通过选择合适的时间步长,可以在大幅减少运算量的同时,没有漏掉任何历史信息,从而在识别准确性和运算量之间取得平衡。
tdnn的输入特征是每秒100帧(每10毫秒一帧)的原始帧速率,输出的帧速率降低之后是每30毫秒一帧,所以需要修改hmm拓扑结构。传统的hmm拓扑是一种从左到右的3-state结构,可以至少在三帧内穿越。tdnn使用的拓扑结构可以在一帧内穿越,具有只能出现一次的状态,然后有可能出现零次或多次的另一种状态。所以单个HMM可以发出a或ab或abb等不同的状态,其中b可以理解为ctc中的blank。
使用新的拓扑结构和基于GMM模型相同的过程来获得状态聚类。
Training on frame-shifted data
我们在之前已经有产生扰动数据的方法来人为地增加我们训练的数据量,在chain model中我们还可以额外的通过帧移位的方式来增加数据。
tdnn的输出帧速率是常规帧速率的三分之一(可配置),这意味着我们只在t值为3的倍数时评估网络的输出,因此我们可以通过对训练数据进行帧移动来生成不同版本的训练数据,例如移动0,1和2帧。这是在训练脚本中自动完成的,当我们从磁盘读取训练示例时,nnet3-chain-copy-egs具有由脚本设置的-frame-shift选项。这其实影响的是epoch的数量,例如用户请求4个epoch,那么实际上训练12个epoch,我们只是在3个不同版本的数据上这样做。实际上,选项–frame-shift = t选项的作用是将输入帧移动t,并将输出帧按3到t的最接近的多重值移动。 (通常它可能不是3,是名为–frame-subsampling-factor的配置变量)。
参考:
http://www.zongchang.net/a/kuaibao/20727.html
Purely Sequence-Trained Neural Networks for ASR Based on Lattice-Free MMI
